|
C. Shih
Одним из недостатков поиска по ключевым словам, однако,
является то, что он не учитывает контекст. Например, поиск Google не принимает
во внимание разные типы данных в Интернете: является ли искомое слово чьим‑то
именем, названием места, песни, одежды или чем‑то еще? Хотя фразу для поиска
можно и уточнить (написав, например, «Canon 5 мегапикселей цифровая камера»,
чтобы не получать результаты, касающиеся пушек, канонов и т. п.), во многих
случаях это сделать сложно. Особенно сложно иметь дело с омонимами. Например,
словосочетание «Paris Hilton» может обозначать как человека, так и гостиницу
(более того, несколько гостиниц и нескольких людей). У слов часто бывает много
значений, и они могут зависеть от контекста.
Поскольку количество информации, наполняющей Интернет,
продолжает расти взрывообразно, различение значений слов и контекстов их
употребления будет ключевым фактором в том, чтобы Интернет оставался
«судоходным» и релевантным. Поняв это, старые медиаигроки, такие как Thomson
Reuters, и молодые стартапы, подобные Metaweb, начали инвестиции в работу по
созданию «семантической Паутины». Их усилия направлены на то, чтобы
классифицировать интернет‑контент так, чтобы он был понятен для компьютеров и
чтобы утомительная работа по связыванию однородной информации в Интернете могла
быть автоматизирована. Например, представим себе семантическую веб‑систему для
продажи букинистических книг через Интернет. Когда кто‑нибудь попадает на этот
сайт впервые, его просят оставить о себе информацию: имя, адрес, электронную
почту, номер телефона. Данные, введенные им, попадают в базу Resource
Description Framework (RDF, «Структура описания ресурсов») и составляют
контекст для будущих его визитов на этот сайт и другие сайты, входящие в
семантическую Паутину. Аналогично любые данные, представленные о конкретной
книге, такие как название, автор, издатель, ISBN и описание, сохраняются в
аналогичной базе RDF. Таким образом постепенно создается универсальная база
знаний о разных людях, местах, объектах – на основании их смысла, наличия
связей в Интернете и отношения друг к другу. В дополнение к метаданным о
контенте Интернета уникальные характеристики, предпочтения и история поисков,
проведенных разными людьми, также образуют важный контекст для каждого поиска.
Нынешние поисковые машины в большей или меньшей степени построены на
предположении, что все люди одинаковы. То есть если результаты моего поиска
релевантны для меня, то они будут релевантны и для вас, будь вы 90‑летней
бабушкой, 12‑летним мальчиком или крестьянином из Найроби.
Поведенческое таргетирование пытается заполнить этот пробел,
создавая профиль каждого интернет‑пользователя на основании его биографических
данных и истории его деятельности в Интернете и затем показывая ему только ту
рекламу, которая ему будет заведомо интересна. Рекламные сети и некоторые
порталы, такие как AOL и Yahoo, уже почти десятилетие используют поведенческое
таргетирование, чтобы показывать пользователям рекламу и контент, основываясь
на их прошлой истории – посещенных сайтах, длительности визитов, нажатых
баннерах и покупках. DoubleClick (приобретенный Google) был в свое время
лидером в разработке таргетирования рекламы при помощи куков. В последнее время
такие компании, как Tacoda (купленная AOL), Revenue Science, Front Porch,
NebuAd и Phorm, возродили эти методы для использования широкополосными
провайдерами, которые имеют доступ к гораздо большему количеству данных о веб‑активности,
поскольку обрабатывают трафик своих пользователей, направленный ко всем
возможным сайтам, в отличие от обработки трафика на стороне сайтов, входящих в
небольшой круг. Понятно, что поведенческое таргетирование вызвало к жизни целую
волну дискуссий о вопросах сохранения приватности, поскольку в большинстве
таких систем пользователи не дают в явном виде разрешения на такой доступ к их
данным и даже часто не имеют возможности и отписаться от него и, таким образом,
не могут контролировать, какая информация о них собирается и как она
используется.
Будущее: социальное фильтрование
Сегодняшний бум
«каждый – издатель» привел к взрывному росту онлайнового контента. Люди уже не
смогут самостоятельно обработать всю имеющуюся информацию. С точки зрения
отдельного человека, большая часть того, что он видит на экране компьютера, –
это мусор. Хотя поисковые машины и поведенческое таргетирование были первыми и важными
шагами к тому, чтобы сделать изобилие онлайновых медиа более управляемым,
продолжается тяжелая битва за преодоление гор информации и борьба с
отвлекающими факторами. Мы продолжаем кажущуюся бесконечной войну со спамом в
наших почтовых ящиках. Когда мы ищем информацию, нам приходится пролистывать
десятки страниц результатов поиска, не содержащих ничего для нас интересного.
Навязчивые всплывающие баннеры, рекламирующие совершенно ненужные нам товары и
услуги, блокируют экран как раз в тот момент, когда мы хотим прочитать с таким
трудом найденную интересную статью.
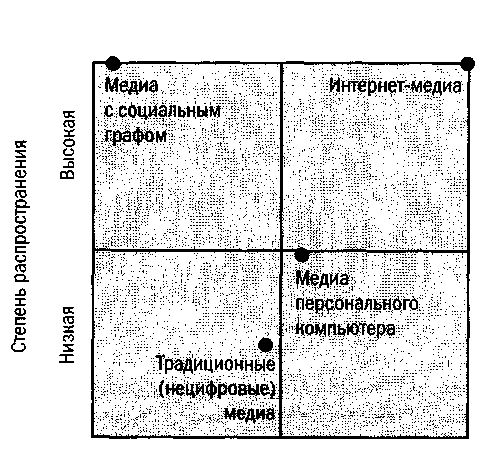 Но надежда еще не умерла. Онлайновый социальный граф может
дать нам возможность впервые найти соответствие между тем, что издатели и
рекламисты хотят нам показать, и тем, что пользователи хотят увидеть (см. рисунок). Но надежда еще не умерла. Онлайновый социальный граф может
дать нам возможность впервые найти соответствие между тем, что издатели и
рекламисты хотят нам показать, и тем, что пользователи хотят увидеть (см. рисунок).
До возникновения социального графа большее
распространение приводило к большему количеству мусора. С помощью социального
графа мы можем использовать наших друзей в качестве фильтров для поиска нужного
нам контента и данных в нужное время
Например,
формируется
«подталкиваемый» контент: люди в Facebook и Twitter уже сейчас могут
организовывать социально отфильтрованные ленты новостей, извещения и СМС‑сообщения,
касающиеся веб‑страниц, статей, фотографий и постов в блогах. То есть контент,
получаемый пользователем, зависит от рекомендаций его друзей. Такие извещения
воспринимаются как менее навязчивые не только потому, что их получатели сами
могут регулировать частоту и формат их получения, но и потому, что получаемая
ими информация касается людей, которых они знают и о которых волнуются. Вы с
меньшей вероятностью сочтете спамом сообщение, полученное от друга или от того,
за кем вы следите в Twitter. Наоборот – большинство людей считают найденный их
друзьями контент интересным и релевантным.
FriendFeed, основанный бывшими работниками Google, является
«лентой лент», способной собирать обновления по всему Интернету, включая блоги,
сайты микроблогов вроде Twitter, сайты социальных сетей вроде Facebook и любые другие
потоки RSS или Atom. Участники FriendFeed могут настраивать свои ленты,
делиться ими с друзьями, впервые создавая таким образом всеобъемлющий и
систематический опыт пропускания веб‑контента через социальные фильтры. Сайты
социальных сетей становятся новым типом интернет‑порталов. С точки зрения
пользователя, все содержание сайта социальной сети индивидуализировано и
персонализировано. Сравните, как выглядят сегодня другие сайты. Каждый зашедший
на сайт YouTube, Yahoo или BBC.com видит то же самое, что видят все остальные.
Даже Amazon, com, в высокой степени персонализированный на основании информации
о предыдущих покупках и поисках пользователя, не выглядит личным. Amazon.com не
имеет никакого понятия о том, кто мы такие, где живем и с кем дружим. На Facebook,
наоборот, никакие два посетителя не видят одно и то же. Войдя в систему,
пользователи попадают в круг друзей, у каждого свой.
«Вытягиваемый контент» – то есть контент, доступа к которому
люди сами активно добиваются, – это сочетание социальных фильтров и профилей
подписки, созданных и управляемых с амими пользователями. Он может дать более
качественный и более персонализированный опыт использования Интернета.
Например, при расчете релевантности результатов поиска можно придавать больший
вес предпочтениям и мнениям друзей или других пользователей с аналогичными
профилями. В табл. 2.1 показано, что мы можем начать использовать помощь
своих друзей для отсечения мусора и поиска контента, интересного и полезного
для нас лично. При этом мы не будем чувствовать, что как‑то нарушается наша
приватность, если содержимое рекламных объявлений будет появляться в результате
рекомендаций наших друзей и если у нас есть возможность контролировать, какая
информация о нас доступна и как она используется – в отличие от скрытого от нас
и не управляемого нами создания профилей, происходящего в большинстве систем
поведенческого таргетирования. амими пользователями. Он может дать более
качественный и более персонализированный опыт использования Интернета.
Например, при расчете релевантности результатов поиска можно придавать больший
вес предпочтениям и мнениям друзей или других пользователей с аналогичными
профилями. В табл. 2.1 показано, что мы можем начать использовать помощь
своих друзей для отсечения мусора и поиска контента, интересного и полезного
для нас лично. При этом мы не будем чувствовать, что как‑то нарушается наша
приватность, если содержимое рекламных объявлений будет появляться в результате
рекомендаций наших друзей и если у нас есть возможность контролировать, какая
информация о нас доступна и как она используется – в отличие от скрытого от нас
и не управляемого нами создания профилей, происходящего в большинстве систем
поведенческого таргетирования.
|

 Приветствую Вас Гость | RSS
Приветствую Вас Гость | RSS
